GridWorld는 30(5x6)개의 이산적인 공간으로 되어 있기 때문에 Q-가치를 딕셔너리에 저장해도 충분하다.
하지만 상태 개수는 문제에 따라서 매우 클 수 있고, 무한하게 큰 경우도 존재한다.
이산적인 상황이 아닌 연속적인 상황도 존재한다.
문제를 해결하기 위해 가치 함수 V(S_t)나 행동-가치 함수 Q(S_t, A_t) 같은 테이블 형태의 데이터 포맷으로
가치 함수를 표현하는 대신 함수 근사 방식(function approximation)을 사용한다.
근사 함수 q_w(x_s, a)가 심층 신경망일 때, 만들어진 모델을 심층 Q-네트워크(DQN)이라고 한다.
가중치는 Q-Learning 알고리즘에 의해 업데이된다.
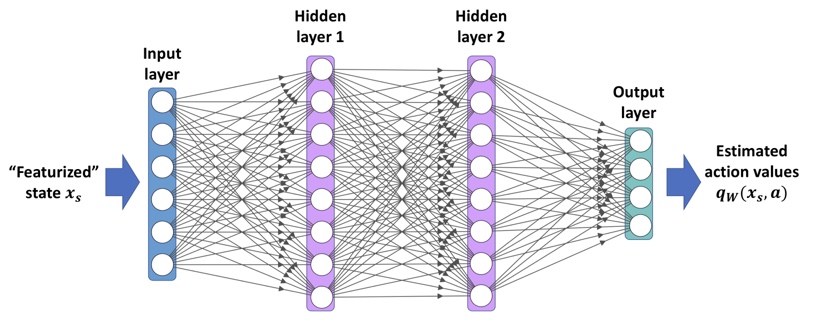
행동 가치를 계산하는 다층 신경망을 사용한다는 점을 제외하면 Q-Learning과 동일하게 훈련한다.
DQN Training with Q-Learning Algorithm
재생 메모리
agent.py의 choose_action() 메서드에서 Q-Learning을 위해 단순히 행동 가치를 참조하여 딕셔너리에 저장하였다.
테이블 방식을 사용하면, 다른 값에 영향을 미치지 않고 특정 상태-행동 쌍의 가치를 업데이트 할 수 있다.
DQN에서는 신경망 모델로 q(s, a)를 근사하기 때문에 상태-행동 쌍을 위해 가중치를 업데이트하면
다른 상태의 출력에도 영향을 미친다.
예를 들어 지도학습에서 확률적 경사 하강법으로 신경망을 훈련하려면, 모델이 수렴할 때까지, 훈련 데이터로
여러 번 에포크를 반복한다.
에피소드가 훈련하는 동안 변경되고 이로 인해 훈련 초기에 방문했던 일부 상태를 나중에 덜 방문하게 되기 때문에
Q-Learning에 사용하기 어렵다.
신경망을 훈련할 때, 훈련 샘플이 독립 동일 분포(Independent and Identically Distributed, IID)라고 가정한다.
에이전트의 에피소드에서 얻은 샘플은 연속된 전이를 형성하기 때문에 IID가 아니다.
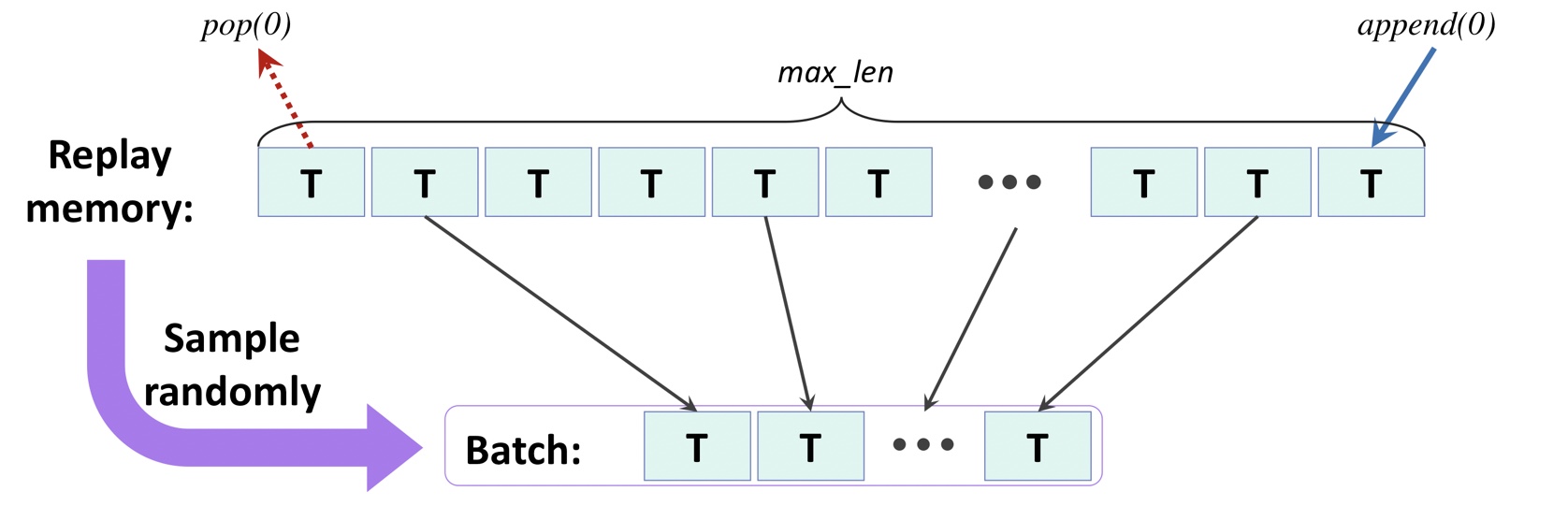
재생메모리(replay memory)라고 부르는 메모리 버퍼에 많은 횟수의 전이를 저장한다.
(에이전트가 환경에서 행동을 선택하고 실행한 후) 만들어진 새로운 전이 5원소를 메모리에 추가한다.
메모리 크기를 제한하기 위해서 가장 오래된 전이는 메모리에서 삭제
재생버퍼에서 미니 배치 샘플을 랜덤하게 선택해서 손실을 계산하고 신경망의 가중치를 업데이트
파이썬에서 리스트로 재생 메모리를 구현할 수 있다.(pop(0)을 통해 리스트의 크기를 확인)
collections 라이브러리의 deque 데이터 구조를 사용해서 재생 메모리 구현 가능하다.
리스트에서 첫 번째 원소를 제거하는 것은 O(n)의 복잡도를 가지지만 deque에서는 O(1)의 복잡도를 가짐
손실 계산을 위한 타깃 가치 결정
DQN 모델 파라미터를 훈련하기 위한 업데이트 규칙을 적용하는 방법을 바꾸어야 한다.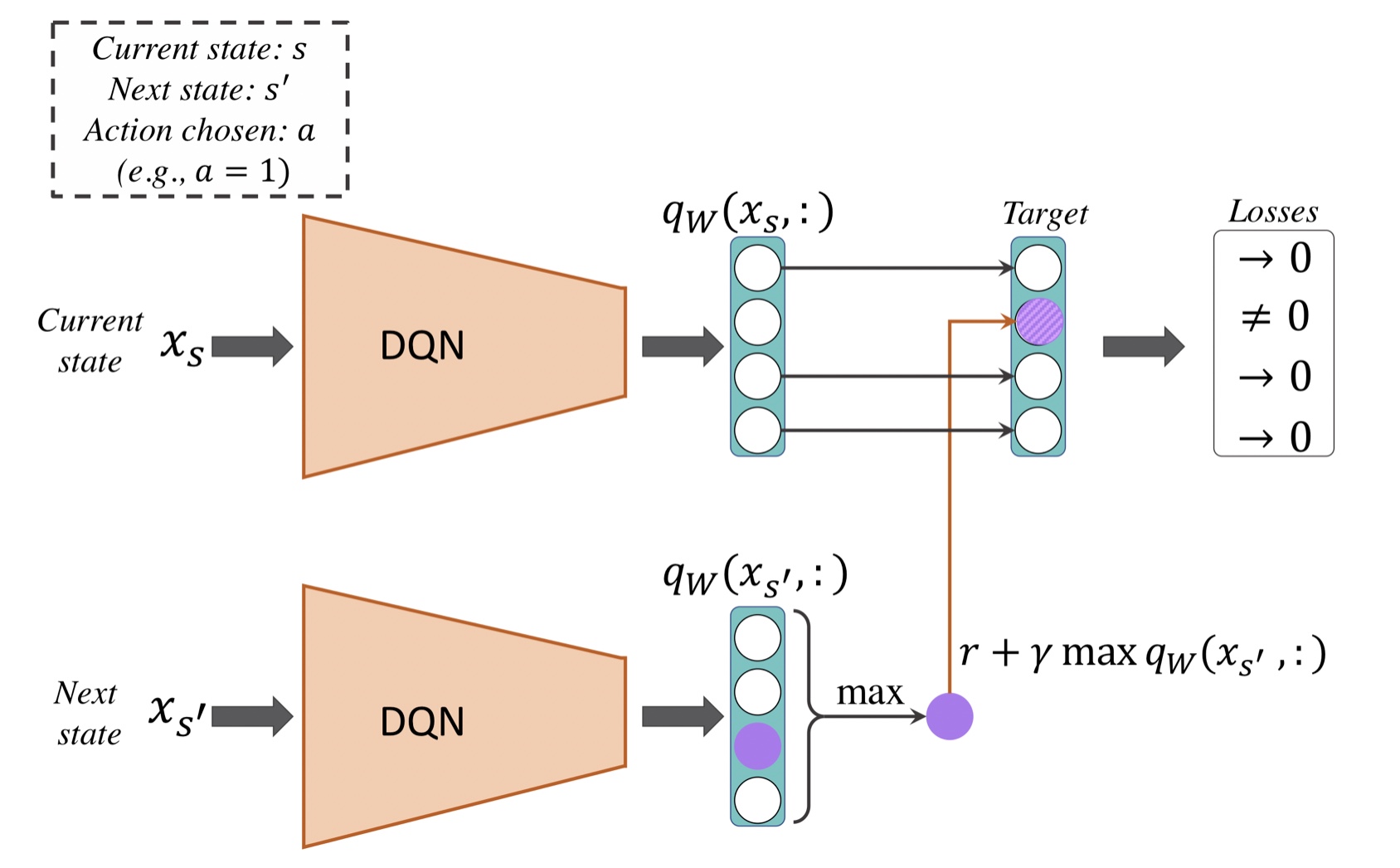
재생 메모리 전이 5원소 T는 (x_s, q, r, x_s, done)을 담고 있다.
DQN은 정방향 계산을 두번 수행한다.
첫번째 계산은 x_s를 두번 째 계산은 x_s’을 특성으로 사용
DQN은 특성에 대하여 q_w(x_s, :), q_w(x_s’, :)을 반환한다.
(모든 행동에 대한 Q-가치 벡터)
Q-Learning 알고리즘에 따라 상태-행동 쌍(x_s, a)에 해당하는 행동 가치를 스칼라 타깃 가치
r+gamma*max(q_x(x_s’, a’)로 업데이트한다.
심층 Q-러닝에 대하여 참고
머신러닝교과서with파이썬,사이킷런,텐서플로_개정3판pg.805